In a previous blog introducing IBM Watson for Embed, I introduced the IBM Watson Libraries for Embed. They provide a common framework to help ISVs embed AI including natural language processing (NLP) and speech into their solutions.
The Watson Libraries are shipped as containers which can be run standalone for testing and learning, but when it’s time for a more scalable environment, it’s likely you’ll want to deploy to a Kubernetes platform. Further more, if you’re frequently creating and destroying environments (i.e. for POCs, demos, production etc), then you can benefit from ‘Everything as Code’ automation using the IBM TechZone Deployer, which is the focus of this blog.
Automate ‘Everything as Code’ using a combination of Terraform and Argo CD
The main advantage of handling infrastructure as code is that with a declarative approach, changes can tracked easily and human errors can be reduced.
Terraform is a popular and established tool to set up infrastructure on any cloud, and there is huge community support.
GitOps not only handles infrastructure as code, but also custom applications and other Kubernetes resources. Here is the definition of GitOps from Red Hat.
“GitOps uses Git repositories as a single source of truth to deliver infrastructure as code. Submitted code checks the CI process, while the CD process checks and applies requirements for things like security, infrastructure as code, or any other boundaries set for the application framework. All changes to code are tracked, making updates easy while also providing version control should a rollback be needed.”
GitOps uses Git repos to define the desired state of a system. GitOps tools like Argo CD compare the current state with the desired state. If they don’t match, synchronisation is triggered automatically to apply, update or delete resources.
To automate the set up and ongoing management of complete software solutions, Terraform and Argo CD can be used together: Terraform for infrastructure like Kubernetes clusters and Argo CD for everything within Kubernetes clusters. This is why IBM has built an opinionated framework which combines the strengths of these tools. The open source IBM TechZone Deployer provides a catalogue of modules which can be used to automate all layers of a solution including:
- Infrastructure
- On public clouds including AWS, Azure & IBM Cloud
- Hybrid Platform
- Red Hat OpenShift on AWS (ROSA), Azure (ARO) or IBM Cloud
- Software
- IBM software, ISV software, Open Source etc
- DevOps
- Use GitOps to automate solution deployment to existing or entirely new environments
IBM TechZone Deployer provides a catalog of over 200 modules to install the layers above. This includes modules which set up Argo CD in a Kubernetes or OpenShift cluster, and creates a Git repo which is linked to Argo CD. With a little know how, ISVs can create their own modules which can be used in combination with those from the catalog.
Complete solutions are defined in yaml files. These bill of materials contain a list of modules from the public or a private catalog, and each module has its own customisable properties.
There is also a CLI called iascable. It is used to convert the bill of materials into Terraform assets. A container image is also provided which comes with all tools necessary to run the generated Terraform.
Deployment Automation of Watson NLP Library for Embed
In the example bill of materials file, the following layers are configured:
- OpenShift in the IBM Cloud
- Argo CD including a GitOps repo
- Watson NLP library container including one pre-trained model
- A ‘UBI’ application. The name relates to the fact it’s based on a Red Hat Universal Base Image. The UBI application represents a simple ISV application which could use the Watson NLP library
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: cloudnativetoolkit.dev/v1alpha
kind: BillOfMaterial
metadata:
name: cluster-with-watson-nlp
spec:
modules:
- name: argocd-bootstrap
version: v1.12.0
- name: gitops-repo
alias: gitops_repo
version: v1.22.2
- name: terraform-gitops-ubi
alias: terraform_gitops_ubi
version: v0.0.8
- name: terraform-gitops-watson-nlp
alias: terraform_gitops_watson_nlp
version: v0.0.80
The modules in the bill of materials file can be configured via variables, for example regions, resource group names, sizes of clusters. Other variables configure the AI models to load into the Watson NLP library container:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
variables
# overall
- name: region
description: The IBM Cloud region where the instance should be provisioned
value: xxx
- name: resource_group_name
description: The name of the IBM Cloud resource group where the resources should be provisioned
value: xxx
# ocp
- name: worker_count
description: The number of workers that should be provisioned per subnet
value: 2
- name: cluster_flavor
description: The flavor of the worker nodes that will be provisioned
value: bx2.4x16:
To run the sample, you’d need to clone the Watson NLP module repo to access the example bill of material files, and install the iascable CLI.
1
2
git clone https://github.com/IBM/watson-automation
curl -sL https://iascable.cloudnativetoolkit.dev/install.sh | sh
The iascable CLI is used to convert the bill of material into Terraform assets.
1
2
3
cd watson-deployments/roks-new-nlp
iascable build -i bom.yaml
cd output
A container image is provided which comes with all the tools necessary to run Terraform. To start the container, invoke this command in a terminal:
1
./launch.sh
In the running container invoke these commands:
1
2
cd cluster-with-watson-nlp
./apply.sh
The apply.sh command takes approximately 45 minutes to set up the managed OpenShift cluster in IBM Cloud and install the additional modules.
Argo CD will be set up on OpenShift to deploy the Watson NLP library container and the UBI application sample. The Kubernetes resources to achieve this (via Helm charts) are created in the GitOps repo by the Terraform modules. Argo CD deploys the resources to the cluster and ensures the cluster is synchronised with any future updates committed to the GitOps repo, i.e. as a result of a CI/CD pipeline run:

Kubernetes Deployments for the Watson NLP and UBI applications are created on the cluster.
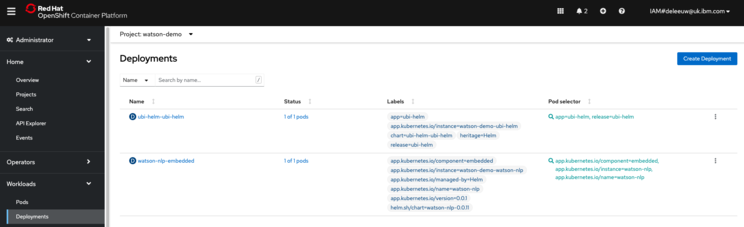
A Service resource allows the UBI or other pods to invoke the Watson NLP libraries:

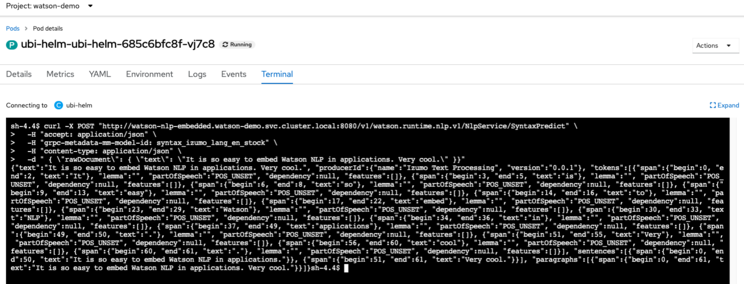
If you were to exec into the container of the UBI application pod, you could use gRPC or REST to invoke the NLP runtime, which was loaded with the IBM provided Syntax model: